Code Archive
아이디어 개요
회사에서 RAG를 이용하여 사내문서 검색기의 데모버전을 만들었었다.
그러다가, 평소에 자주쓰는 함수들을 매번 소스코드에 들어가 찾아다녔던 점이 떠올라 이 RAG를 이용하여 코드검색기를 만들면 좋겠다는 생각이 들었다.
구조는 간단하다.
저장할 코드와 코드에 대한 설명 이 두개를 저장하는데, 코드에 대한 설명을 토크나이징과 임베딩을 하여 저장한다.
그리고 검색할 때 이 임베딩내용과 비교하여 가장 연관성 있는 코드 내용을 가져오게 하는 것이다.
나는 여기서 bm25 와 임베딩 기법을 사용했다.
토크나이징
우선 llm의 기본 구조에 대해 설명하겠다.
문장을 받으면 이걸 컴퓨터가 이해할 수 있도록 수치화를 해야한다.
문장을 쪼개고, id를 부여하고, 해당 id의 가중치를 부여하면 된다.
그 중에 가장 처음으로 하는 문장 쪼개기 즉, 토크나이징은 문장을 특정 방법을 이용하여 쪼개고 id를 부여하는 것을 말한다.

나누는 방법은 단순히 띄어쓰기로 나누거나 단어별로 나누는 등 여러 방법이 있다.
성능을 위해서 한글문장에 최적화된 Okt, Mecab 같은 한국어 전용 토크나이저를 사용하면 좋다.
임베딩
임베딩은 각 토크나이징마다 연관성 점수를 부여한 것과 같다.
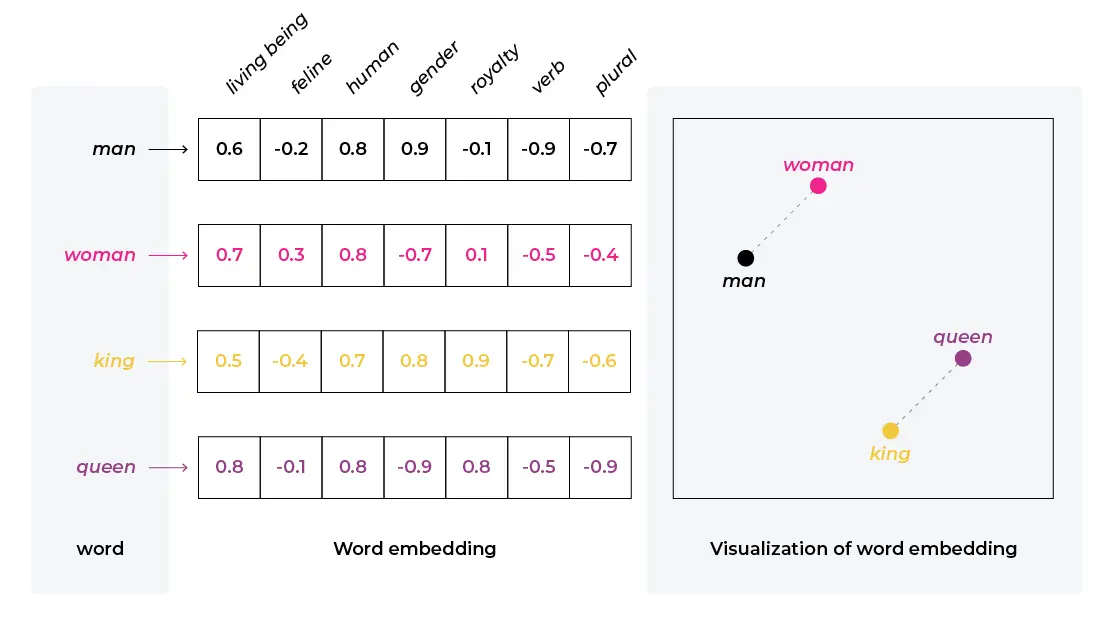
예를들어, 위 이미지처럼 남자와 여자는 서로 연관성이 높기 때문에 가까운 위치로 클러스터링이 되고, 왕과 여왕도 서로 클러스터링이 되는 것이다.
위 이미지는 2차원공간이지만, 실제 임베딩은 더 많은 차원수로 임베딩이 진행되어 더 세세한 연관성 점수를 부여한다.
이러한 특성 덕분에 비슷한 말을 하더라도 연관성으로 인해 융통성있게 이해가 가능하지만, 단점이라면 새로운 토큰이 들어올 때마다 새로 임베딩을 해줘야한다.
추가적인 언어 처리
한국어는 단어 다음말로 인해 앞의 단어의 형태가 달라지는 특성이 있다.
예를 들면, "하얗다" 라는 말은 뒤에 오는말에 따라 "하얗게", "하얀" 등으로 바뀌게 된다.
그러면 똑같은 의미여도 다른 토큰을 가지게 되고, 쓸데없는 연산량이 늘게 된다.
그러기에 이러한 단어를 하나로 통합해주는 과정이 필요하다.
그리고 '은','는','이','가' 등 단어를 이어주는 불용어도 토큰으로는 필요없기 때문에 제거하는 작업 또한 필요하다.
아래는 위의 내용들을 기반으로 작성된 코드이다.
def __sentence_tokenizing(self, query, mode="string"):
lemmatizer = Lemmatizer()
t = Okt()
stopwords=['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
query = re.sub(r"[^\uAC00-\uD7A30-9a-zA-Z\s]", "", query)
if mode == "string":
lemm_sentence = ''
for text in t.pos(query):
if text[0] in stopwords:
continue
result_lemm = self.__find_elements_with_specific_value(lemmatizer.lemmatize(text[0]),text[1]) #0 = 텍스트, 1 = 품사
if len(result_lemm) == 0:
lemm_sentence += f"{text[0]} "
else:
# print(result_lemm)
lemm_sentence += f"{result_lemm[0]} "
elif mode == "array":
lemm_sentence = []
for text in t.pos(query):
if text[0] in stopwords:
continue
result_lemm = self.__find_elements_with_specific_value(lemmatizer.lemmatize(text[0]),text[1]) #0 = 텍스트, 1 = 품사
if len(result_lemm) == 0:
lemm_sentence.append(text[0])
else:
lemm_sentence.append(result_lemm[0])
return lemm_sentence랭킹알고리즘 bm25
bm25는 임베딩은 아니고, 검색엔진 알고리즘에서 자주 쓰이는 랭킹알고리즘 중 하나이다. tf-idf의 상위버전이며, 특정 단어의 빈도수에 따라 점수를 부여하여 가장 연관성 있는 문서를 찾아낸다.
단어의 빈도수이기 때문에 단점이라면 해당 문서에 특정단어가 비정상적으로 많이 나오기만 해도 해당 문서가 정답문서로 오인하기도 한다.

bm25와 임베딩
임베딩의 단점은 bm25보다 더 세밀한 검색을 하지만 속도가 많이 느리다. 그리고 bm25는 검색속도는 빠르지만 특정단어에만 의존성이 크다.
그래서 이 둘의 장점을 이용해보았다.
bm25를 이용하여 가장 연관성이 높은 문서 10개를 순위별로 추려낸다.
그 다음, 임베딩을 이용하여 10개의 문서의 순위를 재순위시킨다.
그리고 상위 문서들을 가져오게하는 것이다.
참신한 아이디어였지만, 실험결과 bm25를 단독으로 썼을 때와 그다지 큰 차이를 보이지 못했다.(실험결과 자료가 날라가서 없다...)
나중에 기회되면 다시 도전해볼 예정이다.
참고
후기
현재 codeArchive는 tomatoAgent 프로젝트에 적용하고 있다.
로컬환경에서는 동작확인이 됐는데, db로 연결하면서 로직이 꼬이게 되어 추가작업이 피룡하여 아직 구현이 완료되지는 않았다.
빠른 시일내에 도입할 예정이다.